
The Internet seems endless, and no one can predict its size exactly! The general public thinks that Facebook, YouTube, Amazon, Microsoft, and sites found via Google search engine constitute what is now known as the Internet, however, this is wrong. This is only the surface of the web.
What most internet users see when going online is known as the Surface Web, which constitutes less than 5 % of the entire web content. The Surface Web is only the tip of the big iceberg.
If you run OSINT investigations or if you have to support the decision-making process, you really should take care of the remaining 95 % even if effort and complexity will cause you endless nights.
Before we begin discussing the internet capacity and its various layers, it is essential to distinguish between two terms that the general public uses interchangeably which are: the Internet and the World Wide Web (WWW):
- WWW is the collection of websites (webpages, digital files, and anything contained within a website).
- Internet is the network (or infrastructure) used to access web content.
This always reminds me of the discussion bandwidth vs. data rate: 100 MBit/sec is not bandwidth!
Let’s proceed with some interesting facts: The number of people accessing the Internet is accelerating at an explosive rate. According to Statista, almost 4.57 billion people were active internet users as of April 2020, encompassing 59 percent of the global population.
This is a huge number and is expected to reach 7.5 billion Internet users by 2030 (this is equal to 90 percent of the projected world population of 8.5 billion, 6 years of age and older) according to Cybersecurity Ventures. The increased number of internet users will produce a huge amount of digital data from their interactions in cyberspace. You can expect that all layers will grow within the next 10 years.
This collection of public information opens numerous opportunities for OSINT gatherings to conduct all types of online investigations, as shown in our previous articles on Social Media Investigations or on OSINT tools.
This article is dedicated to describing the main layers that constitute the WWW which is:
- Surface Web,
- Deep Web,
- and Darknet.
Knowing how to search within each layer is considered a key skill for any serious OSINT investigator.
Surface Web
Also known as the Visible Web, this is the portion of the web which is accessible by the general public when you run a web search using regular search engines such as Google and Yahoo! The content of the Surface Web is intentionally indexed by search engines, so its contents can be found easily compared with other internet layers. To know what we mean by the term “indexed”, we should understand how search engines work.
How Search Engines Index Web Content
When you submit a search query, the search engine will not perform the search directly across the web. Instead, it will search within its own database and return relevant results accordingly. By the way, this is different to the way of working of our Federated Search.
To create these index databases, search engines use web crawlers, also known as web spiders or bots. Think of the crawler as an automated script that travels across the web to discover new content. When a web spider discovers a new page, it follows all hyperlinks.
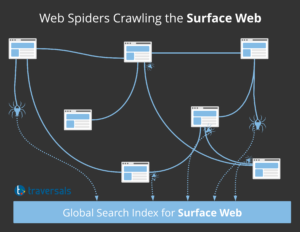
The result of the crawling process is sent back to the global search index, which is a gigantic database organizing all discovered contents in a way that facilitate easy information retrieval. To assure a high level of accuracy, search engines will not add all discovered webpages to the index database, as the information within the discovered webpages should have a value (e.g. it is original, up to date, accurate and from a reputable domain name) for the searcher to be considered in the index database.
Now, when a user accesses a search engine, such as Google, and submits a search query, the search engine will take the user search query and look up the result in the search index. To provide nice user experience, search results return deterministic: If you run the search twice within short time, the results will be the same.
To achieve this, search engines use a complex algorithm for result ranking to deliver the best answer to searcher’s query. Keep in mind that the ranking of Google is different from Yahoo, Yandex, Bing, … This often complicates your OSINT investigations and is also the reason why we apply a customer-specific ranking on top of all results coming from different data sources.
Using search engines offers a convenient way for internet users to surf the web. You as a website provider can even trigger and influence the indexing process. However, many web pages are not crawlable, and this leads us to the next layer of the web, the Deep Web.
Deep Web
Deep web, also known as Hidden Web, is the part of the WWW that typical search engines cannot index. This layer constitutes the biggest part of web content (around 95 %) and contains within another layer called the Darknet.
Contents on the Deep Web cannot be indexed because:
- it is either protected with a password, such as your cloud storage, webmail solution, digital libraries, online magazines, or newspapers.
- or it is stored behind web services or APIs preventing direct access to the raw data.
Deep web contents are of special interest for OSINT investigations. Often you get high-quality information on your target, such as ownership information on a certain organization. At Traversals, we are constantly monitoring new services and decide if it is worth the effort to integrate those into our Federated Search solution.
Both Surface and Deep Web contents can be accessed without using any special software, unlike Darknet which requires installing specific software to access.
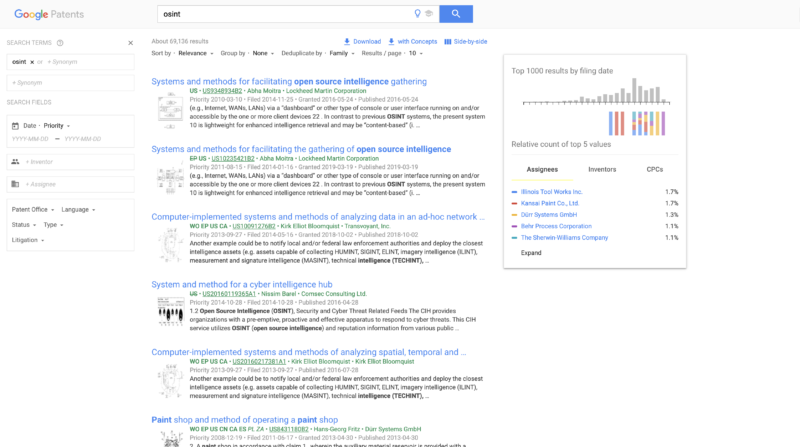
There are many deep web data sources available:
- Google patent database for patents worldwide. This information is really interesting when it comes to Competitor Intelligence.
- Google academic database for research articles. This information is also interesting for Competitor Intelligence.
- EU Sanction Lists which is really useful for running Vendor Risk Management.
- HaveIBeenPwned which enables Data Leakage Detection and also background checks.
- Zabasearch, being a free US people and public information search engine.
- Many many more…
Darknet
Darknet (also known as the Dark Web) is the deepest layer of the web and belongs officially to the Deep Web. However, unlike the Deep Web, which does not require software to access, a user must use dedicated software to access it, such as TOR or I2P. There are even combinations possible, such as BitTorrent Darknets, which makes it more and more complex.
Darknet contains websites that have been intentionally created to be hidden. It becomes obvious when you see TOR URLs, such as http://kpynyvym6xqi7wz2.onion/links.html: impossible to guess, pretty hard to remember, no chance of identifying the purpose of the website, …
Although some specialized search engines facilitate looking up information on the Darknet, they are not that accurate because of the ephemeral nature of the Darknet sites. Thus, specific Darknet URLs are often shared between users.
The Darknet name was always associated with black markets and illegal activities such as drug dealing, gun supplying, human trafficking, selling false government documents, selling breached accounts credentials, trade secrets, and many more.
This black side does not mean Darknet websites are all illegal per se. For instance, there are a considerable number of sites hosted on the darknet that belong to human rights activists, journalists, and political protests that want to conceal their identity.
As written in our article on OSINT investigations, the same Darknet technology is commonly utilized by OSINT investigators to conceal their traffic when searching the surface and deep web.
Key Findings
- World Wide Web is composed of three layers: Surface Web, Deep Web and Darknet.
- The Surface Web covers only 5 % of the World Wide Web.
- Deep Web includes any kind of web service and constitutes a very interesting data source for OSINT investigations.
- Darknet can be accessed only by using dedicated technology, such as TOR or I2P.
- Darknet is not only used for illegal activities but also for actions in which anonymity plays a role, such as journalism in crisis areas.