
The Need to Understand the World
The world has turned into a global village, still protected by real borders, but without frontiers for virtuality. Globalization engendered a worldwide network of distributed points of interest that may influence each other. Any conflict or crisis in one country can set off a chain reaction in other parts of the world:
A stranded ship led to worldwide problems in the industry in April 2021. The consequences are still being felt today.
Deviations from normality are of high interest for politicians, government entities, trade and industry, NGOs, or news agencies. Researchers and analysts try to find answers to these questions every day, e.g.
Where and when does the next deviation or conflict occur, and what is its impact on our society?
Unfortunately, it happens all too often that we are surprised by new situations, although the information about them was already available.
Looking at the complex and interconnected events that took place in Afghanistan in August 2021 retrospectively, sufficient information was available that could have led to the conclusion that the situation would evolve the way it did. Experts already agree that the consistent evaluation of publicly available information or Open-Source Intelligence (OSINT) would have contributed to a better situation picture.
While capturing publicly available information has never been as easy as today, turning that information into actionable intelligence remains one of the biggest challenges:
How can we reduce the amount of freely available information (OSINT) to focus our resources on the truly valuable and pertinent information we need to better understand the world?
This article introduces a new core feature of our Data Fusion Platform which is based on OSINT and supported by Artificial Intelligence to detect global conflicts, crises, or anomalies of any kind in near real-time. The article describes the full journey starting with some first ideas and finishing with bringing the feature into production.
Existing Systems to Get Categorized Conflict Information
Analysts and researchers today, trying to understand the world by evaluating freely available information, face a host of constraints and obstacles. They quickly reach the limits of what is humanly possible:
They normally do not speak 200 languages and cannot read 100 million articles per day.
Therefore, they need assistance systems of any kind that do the hard work for them by providing already pre-categorized/pre-filtered data. We have deliberately chosen different examples of already existing possibilities:
- Global Database of Events, Language and Tone (GDELT): The GDELT project collects information from a wide variety of data sources and categorizes it using the Conflict and Mediation Event Observations (CAMEO) Event Codebook.
- Armed Conflict Location & Event Data Project (ACLED): Similar to the GDELT project, the ACLED database collects and categorizes information on conflict situations. The information mostly comes from local partners.
Both the CAMEO and ACLED event codebook are tailored to specific situations, such as military conflicts. From our point of view, this is a strong limitation as more categories are required to understand the complex interrelationships of events like:
A prolonged drought can lead to water shortages and military conflicts.
A blocked channel can cause entire supply chains to be blocked, sending the economy into a tailspin.
To cover all facets of a global crisis and to detect it as early as possible, it is necessary to combine more and diverse event codebooks or protocols.
Why did we implement a new event codebook?
As described in the previous chapter, an event codebook that contains a wide variety of situation descriptions is needed. As a first step, we have taken ACLED and GDELT as a basis and extended them with other codebooks, such as:
- Management of a Crisis (MOAC): It is a vocabulary for describing disasters. It contains categories like Compromised Infrastructure.
- Common Alerting Protocol (CAP): It is a protocol for describing weather phenomena, e.g. heavy rain or heat.
However, events in the recent past have shown that even more categories are necessary to model global events:
- Afghanistan August 2021: There were reports that the tarmacs at Kabul airport had been occupied. This severely impeded the take-off/landing of aircraft and thus the ongoing evacuation.
- …
There were no entries for these events in the existing codebooks. After experimenting over the last few months, we have developed a new event codebook that covers a huge variety of relevant situations:
- Supply chain law: violation of human rights, non-payment of wages, non-compliance with minimum social standards, child labor,…
- Protection of women and girls: sexual or other violence against women and girls, restriction of the rights of women and girls, forced marriage, …
- Freedom of the press: abduction or murder of journalists, prevention of freedom of the press, …

The codebook now contains over 150 different event types, which are used to categorize the information collected by our Data Fusion Platform.
We consider this codebook as a living object that needs to be constantly adapted to existing and additional domains.
Why AI, Machine Learning, Automation …?
As explained in the introduction, the goal is to know about changes as quickly as possible. To do this, information gathering needs to get as close as possible to where the action is. Our Federated Search connects to various data sources, such as Google, Yahoo, Yandex, Naver, Bing, Ahmia, DuckDuckGo, Twitter, Reddit, … and scans multilingual texts and audio for the latest information.
With the multitude of data sources and real-time demand, we generate an incredibly large data stream that is impossible to evaluate manually. Therefore, we need to incorporate AI-based approaches that efficiently pre-evaluate and reduce the millions of daily puzzle pieces of information.
What does an AI-based approach look like?
A First Reduction of the Data Stream
To generate the data stream, our Federated Search connects to various data sources and searches them automatically at regular intervals, using simple keywords that are event-type specific. Unfortunately, more sophisticated searches are not possible, as they are not supported by most of the data sources.
Taking the Forest Fire category from our event codebook as an example, we search for “forest fire” in different languages on Google News or Twitter. Results in foreign languages are transparently translated by our Federated Search. The first processing also includes a Geocoding of text information to allow geospatial analysis.
The following screenshots show the first results and the problems related to simple keyword search.
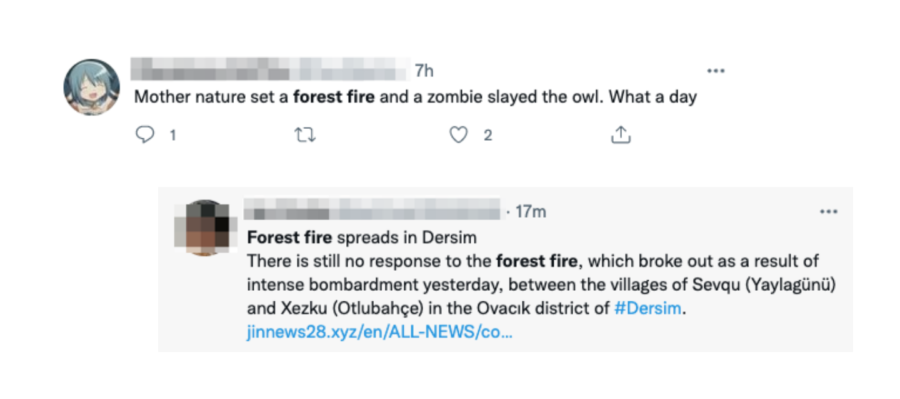
Looking at the results, you can immediately see that a simple keyword search only reduces the data stream.
However, a direct mapping of results to event types is not possible due to the ambiguity produced. It is the poor quality of the first results that is one of the big challenges when it comes to social media analysis.
Final Classification With the Help of AI/NLP
To do the final mapping of the first low-quality results to the event types defined in the event codebook, we started to analyze the sentence structure including all words. This can be done in an automatic way by using state-of-the-art Natural Language Processing (NLP) libraries.

Experiments showed that it is of crucial importance which verbs, nouns, adjectives, tenses, … were used in the text. As we labeled thousands of sample sentences, we could implement a robust feature extraction and feature classification for each event type.
Our training set now contains over 500,000 entries, which are annotated sentence by sentence. Using our own Federated Search allows us to expand this corpus on a daily basis and to adapt it if new event types are added to our codebook.
Now let’s set up MlOps!
After defining our own event codebook and designing robust AI algorithms to map information to entries of this codebook, we faced new challenges:
- Our new event codebook is constantly growing,
- and our training set is getting updated every day.
It turned out that the creation of new AI models is not a static act, but a process that has to be operated on a daily basis.
In addition to that, the German BSI defined in 2021 a new set of criteria for the secure use of machine learning methods in cloud services. The criteria in the Artificial Intelligence Cloud Service Compliance Criteria Catalogue (AIC4) address security and robustness, performance and functionality, reliability, data quality, data management, explainability, and bias.
To get on top of this, we built a Machine Learning Operations (MLOps) pipeline that structures, optimizes and makes the work more efficient and compliant with BSI AIC4. A brief summary of this can be seen in the diagram below.
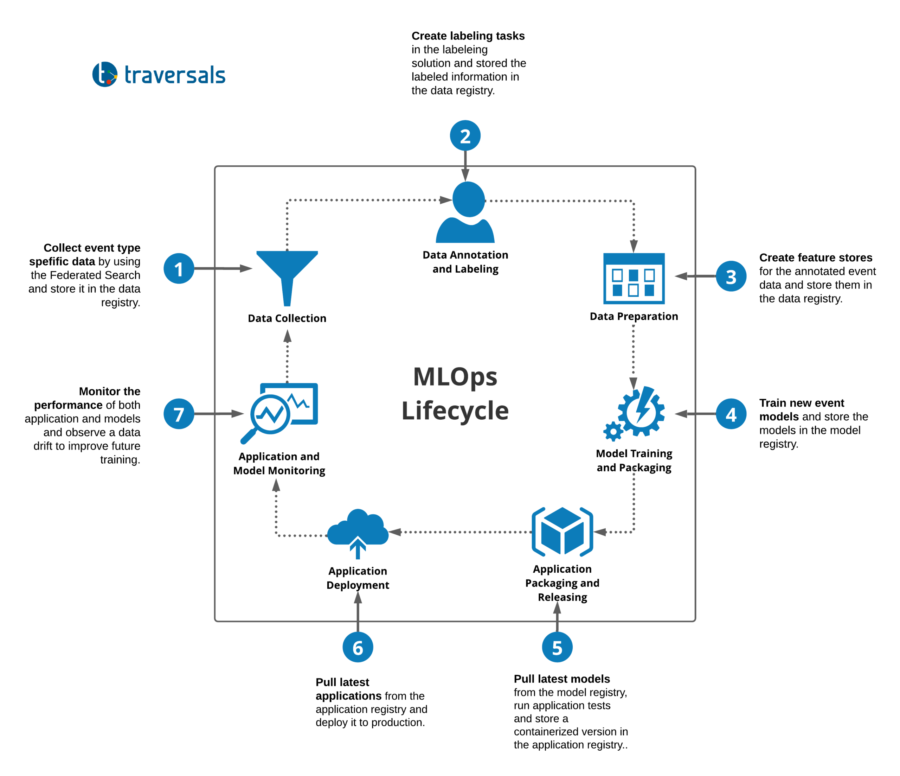
This MLOps pipeline is fully integrated into our architecture and allows daily, reproducible training of AI models for all entries of the event codebook.
Key Findings
- Publicly available information helps us identify and monitor global conflicts.
- Analysis of this publicly available information is still a big challenge making it hard to get reliable situation reports.
- Systems to tackle these challenges are available, but they seem to be incomplete.
- Artificial Intelligence (AI) based analysis of Open-Source Intelligence (OSINT) introduces new capabilities, e.g. near real-time monitoring.
- Machine Learning Operations (MLOps) are required to deal with a constantly growing and self-adapting event codebook.