
Sentiment analysis, or sometimes also referred to opinion or emotion classification, has been around for quite a while. The idea is to automatically judge whether or not a statement, tweet, product review, etc. is biased in a positive or negative way. Explainable AI for sentiment analysis is an add-on that tries to solve a problem well-known in the world of AI: Explainability of results created by AI.
Do you trust results, such as sentiment scores, that cannot be explained?
At Traversals, sentiment analysis is one of the modules which is used to get a better understanding of information collected with the Data Fusion Platform.
It sounds new and science-fiction, but it’s been around for quite some time.
Let’s focus on sentiment analysis first. Early related work dates back to the 60ies: While Stone et al. already describe ways how to analyze content using computers, Gottschalk et al. tried to measure psychological states by analyzing peoples’ verbal behavior.
In the late 90ies, the internet’s success came along with an ever-increasing amount of unwanted email — spam, a somewhat related problem: is an email authentic, or is it junk? In 1996, Sahami et al. published a Bayesian approach to automatically filter unwanted conversations.
Skipping forward well about two decades, deep neural networks show remarkable performance in such natural language processing tasks, but often they have something “magical” to it — they seemed to work great, but no one could actually explain their success in a way that the next guy would understand it.
However, people usually trust machines much more, if their reasoning can be communicated in a sensible way; a concept that’s well known from human-computer interaction: you’re much more inclined to adopt and trust a system that reacts intuitively and foreseeable.
Let’s come back to sentiment analysis. We’re interested in whether a statement, a tweet, or a review is positive or negative.
Tammewar et al. demonstrate and combine three state-of-the-art techniques in deep learning for natural language processing to make an explainable decision: word embeddings, gated recurrent units (GRU) and attention layers. The following sections will explain the idea behind these techniques.
Word Embeddings
Fundamentally, deep learning is the consequent application of linear algebra, analysis and optimization theory (and a lot of compute power and data). Which means, we can’t work with text directly, but we need to find a way to map words to numbers, so they can be used in our mathematical framework.
The most simple way to represent words as numbers is to define them as a base vector in a vector space of a fixed dimension. Let’s say, our vocabulary (the words known to us) are “I”, “love” and “burgers”, then you would define these words as as `[1, 0, 0]`, `[0, 1, 0]` and `[0, 0, 1]` respectively.
Since most languages have quite a lot of (unique) words, the dimension of this “1-hot” encoding is typically in the hundreds of thousands up to millions — clearly, this is not ideal in terms of calculations.
There are several ways to map these huge vectors onto much smaller ones. For example, GloVe by Pennington et al. uses term co-occurrence in a large set of documents to map words into a lower-dimensional space, where the Euclidean distance relates somewhat to semantics:
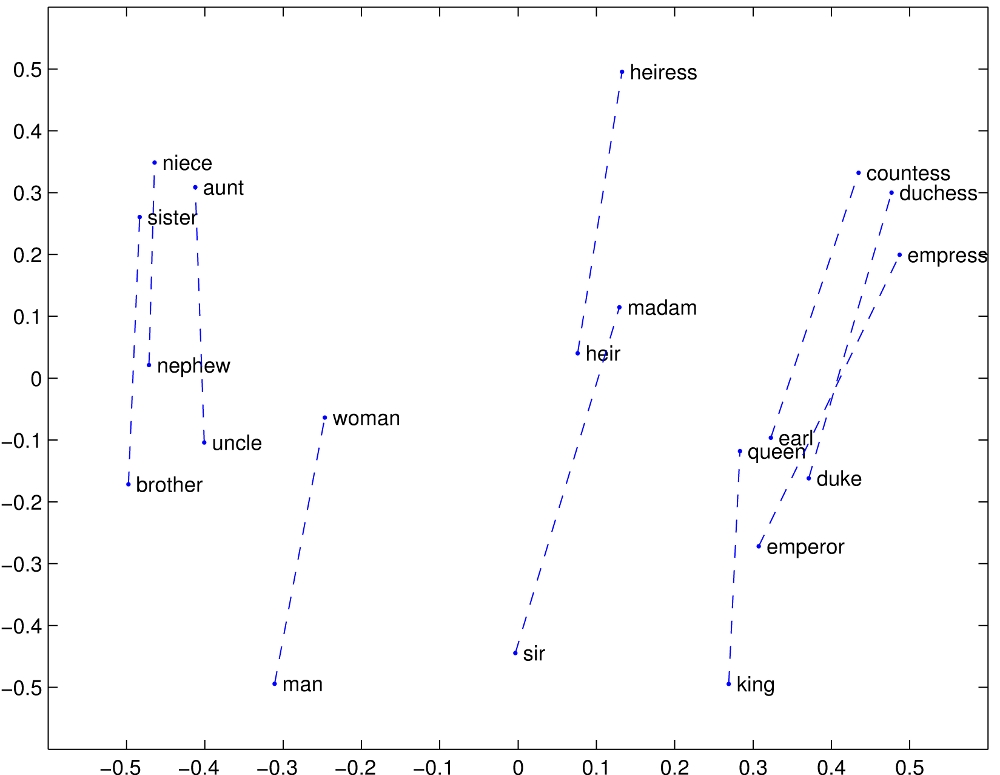
The authors use a layer of unidirectional recurrent neuronal network consisting of GRUs to map this large dimension down to a much smaller one.
While GloVe is typically estimated on a separate set of documents, neural embedding layers can be trained as part of the complete pipeline, thus making them much more tailored towards the actual task at hand.
Gated Recurrent Units
GRUs are a special type of neural network cell that, similar to a real brain, allows to store information in a sort of short-time memory.
Transferred to our text processing example, it means that the order of the words as found in the text makes a difference when processing them one at a time: it allows the GRU to build up an internal state of history that encodes everything it has “seen” so far.
Attention
While recurrence allows the network to memorize things, it behaves a bit like our own short-term memory: it is quickly overwritten, and the more recent an impression, the more present it is.
Attention is a special type of neural network layer, that allows a network to “take a step back” and look at the whole sequence at the same time.
That is, the network gets to see the memory of the GRU layer after each word was observed, allowing it to focus on certain parts of the sentence.
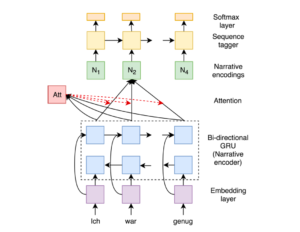
The figure shows the complete network architecture used in this approach to determine if short narratives are positive or negative. At the bottom, words are encoded 1-hot and fed to an embedding layer. The whole sequence of words is then processed by the bidirectional GRU layer (“narrative encoder”) and exposed to an attention layer.
These “narrative encodings” are then classified by a sequence tagger to come up with the final decision, whether a statement was positive or negative. The beauty of the attention-based approach is that this final decision can be “back-traced” to the input, providing an intuitive and visual explanation: We are one step closer to explainable AI for sentiment analysis.

The figure shows two examples for positive and negative narratives each (sorry, it’s German!). Each word is shaded red — the more opaque, the more its contribution to the final decision.
Key Takeaways
- Sentence classification has come a long way — from simple rules using keywords to sophisticated explainable deep learning models.
- For a better understanding and acceptance of those algorithms, it is important that the results are explainable. In that case, we need an explainable AI for sentiment analysis.
- At Traversals, we rely on multiple AI algorithms which help us to understand the information in a more accurate way. Only by doing so, we can fuse the various data sources integrated into the Federated Search.